








/ Interface Design / Dissertation: "key.patcher"
Nowadays search engines in general still work in an old/fashioned library-oriented way. This is of course a sufficient way to look for content that consists of text but it is hard and cumbersome to use this verbal search in order to look for images. Still people do manually index and keyword image data which takes a lot of time and which is sometimes impossible since literally one image can tell you more than thousand words.
So the problem is that search engines can handle just a little part of the whole cultural data adequately, the textcoded data. However this method seems to become insufficient, espacially since the amount of multimedia content is growing rapidly.
But there appears new technology on the horizon that promises at least to unburden people significantly from the task of keywording image data. There is a lot of research about pictorial search engines that would recognize the image content. One of those institutes is Xerox which promises having developed a search engine that would recognize and distinguish between objects in the image like cars, people, animals, buildings etc. In the first step the software extracts characteristic properties the so called "key patches" from the picture and in the second step it tries to assign those to its visual library in order to produce some meaningful keywords.
Glossary
-
Computer vision
Computer vision is the science and technology of machines that see. As a scientific discipline, computer vision is concerned with the theory behind artificial systems that extract information from images. The image data can take many forms, such as video sequences, views from multiple cameras, or multi-dimensional data from a medical scanner. As a technological discipline, computer vision seeks to apply its theories and models to the construction of computer vision systems. Examples of applications of computer vision include systems for: Controlling processes (e.g., an industrial robot or an autonomous vehicle). Detecting events (e.g., for visual surveillance or people counting). Organizing information (e.g., for indexing databases of images and image sequences). Modeling objects or environments (e.g., industrial inspection, medical image analysis or topographical modeling). Interaction (e.g., as the input to a device for computer-human interaction). Computer vision is closely related to the study of biological vision. The field of biological vision studies and models the physiological processes behind visual perception in humans and other animals. Computer vision, on the other hand, studies and describes the processes implemented in software and hardware behind artificial vision systems. Interdisciplinary exchange between biological and computer vision has proven fruitful for both fields. Computer vision is, in some ways, the inverse of computer graphics. While computer graphics produces image data from 3D models, computer vision often produces 3D models from image data. There is also a trend towards a combination of the two disciplines, e.g., as explored in augmented reality. Sub-domains of computer vision include scene reconstruction, event detection, video tracking, object recognition, learning, indexing, motion estimation, and image restoration.
Please read on further information at wikipedia.org
-
Artificial neural network
An artificial neural network (ANN), usually called "neural network" (NN), is a mathematical model or computational model that tries to simulate the structure and/or functional aspects of biological neural networks. It consists of an interconnected group of artificial neurons and processes information using a connectionist approach to computation. In most cases an ANN is an adaptive system that changes its structure based on external or internal information that flows through the network during the learning phase. Neural networks are non-linear statistical data modeling tools. They can be used to model complex relationships between inputs and outputs or to find patterns in data.
Please read on further information at wikipedia.org
-
Thesaurus
A thesaurus is a work that lists words grouped together according to similarity of meaning (containing synonyms and sometimes antonyms), in contrast to a dictionary, which contains definitions and pronunciations. The largest thesaurus in the world is the Historical Thesaurus of the Oxford English Dictionary, which contains more than 920,000 words and meanings.
Please read on further information at wikipedia.org
-
Fisheye
Take a look on some interesting examples of graphical fisheye views:
-

Some thoughts about the topic of image storaging
As long as images are classified by keywords, under conceptual stories or by pseudonyms, one thing will still remain unclear: "How can be an image classified by other means than text?"
The occidental culture of memory, in its expertise and technique of finding, transfering and manipulating/handling the saved image data, is shaped by the word as controlling and navigation tool.
There is no active image thesaurus that would be comparable to the (text based) vocabulary.
In the cinematic montage pictures/images have always been organized and classified according to their visual qualities. Though this task requires a very profound knowledge and experience. So this kind of very exclusive art is dominated by so called cutters who are capable to remember perspectives, compositions, outlines, frames, moving sequences, chroma, luminosity etc. in their extensive image memory.
Until nowadays image data is adressed by words. A written note, a calendar date, the location determine what can be recalled as an image (quality). -

Xerox Technology: The Method
- Detection and description of imagepatterns which are defined by characteristic feature regions
- Creation of a vocabulary - the so called "pattern descriptors" are applied to prefabricated clusters (the vocabulary)
- Creation of the so called "bag of keypoints", which counts the amount of patterns applied to every image
- A multiclass categorizer handles the bag of keypoints as a properties vector and determines which category or categories the image can be applied to
-

Detection and description of imagepatterns
Feature extraction
In the "computer vision" the so-called local descriptors have turned out to be adequate for recognition tasks since they are resistant compared to the theme's partial visibilty and disturbance. -

Feature extraction
How does the machine discover the characteristic regions?
It happens with the aid of the so-called "Harris Corner Detector".The idea is to scan the image with little square units (imagine them as little windows or spyholes) since moving them around in every possible direction produces a big change of the intensity.
As you can observe in the three pics at the bottom the Harris Detector reacts not until it has detected a region with significant changes in all directions which happens when it "sees" e.g. an angle.
-
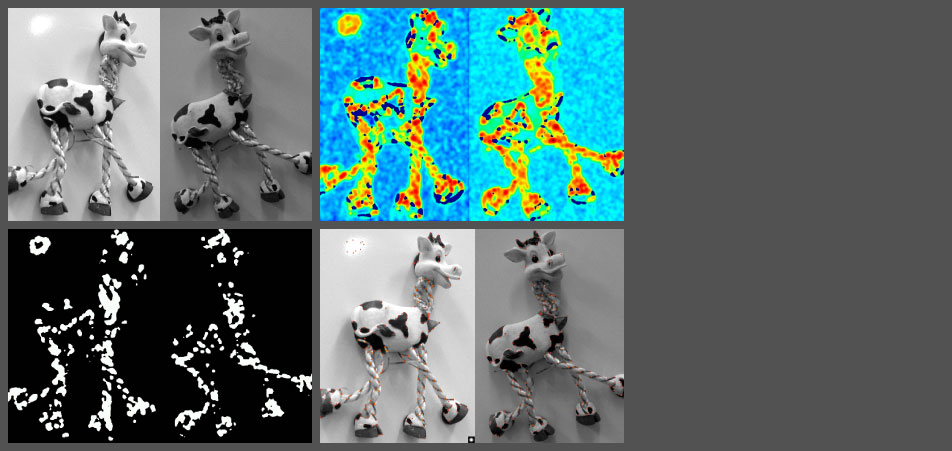
Harris Detector - Procedure
After you fed the machine with a picture (first pic top left) the Harris Detector determines which regions obtain a characteristic visual edge. (second colorful pic top right)
Then the machine makes some selection steps in order to determine the significant feature regions.
-

Harris Detector - Other properties
- The ellipse is rotating though the shape remains unchanged - the "Corner-Resonance" R remains constant compared to image rotations.
- One problem for the Harris Detector is the image scaling. As the "spyhole" remains the same unit size, an edge region on different resolution images can be either determined as "uninteresting" edges or as more "interesting" angles.
- With the aid of an additional function the detector can be also scaled.
- This leads to another problem: How does the machine independently decide which radius it should choose? (I must admit that at this point I leaped to another point since it became too hard to understand for me.)
-
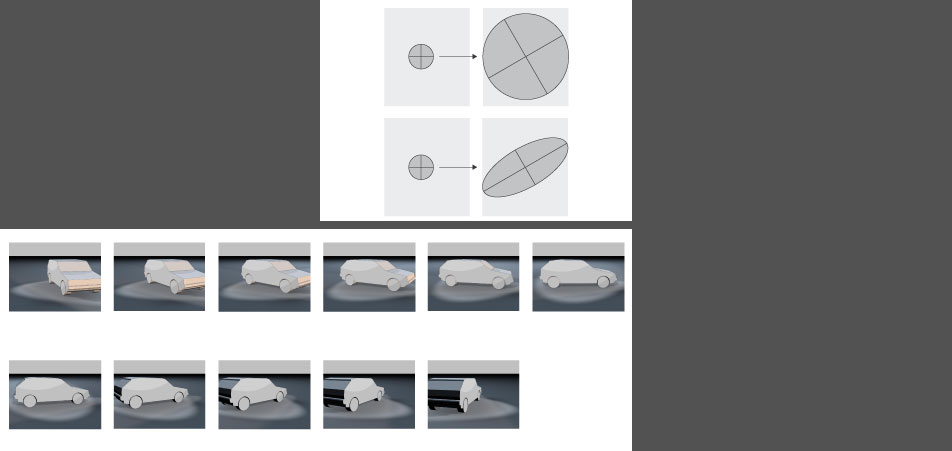
Harris Detector - Affine-compliance detection
So until now we have regarded "similarity transforamtions" like "rotation + uniform scaling".
Moreover the Harris Detector masters also the recognition of the so-called "affine transformations": "rotation + NON-uniform scaling (as one can observe e.g. in the perspective)
Was it necessary until now to feed the machine with different views in order ti teach it a spatial vision, now the "HD" is able to classify spatial distorted objects correctly.
-

Harris Detector - Affine-compliance detection
The region is being distorted and prepared for the assignment of a descriptor.
-
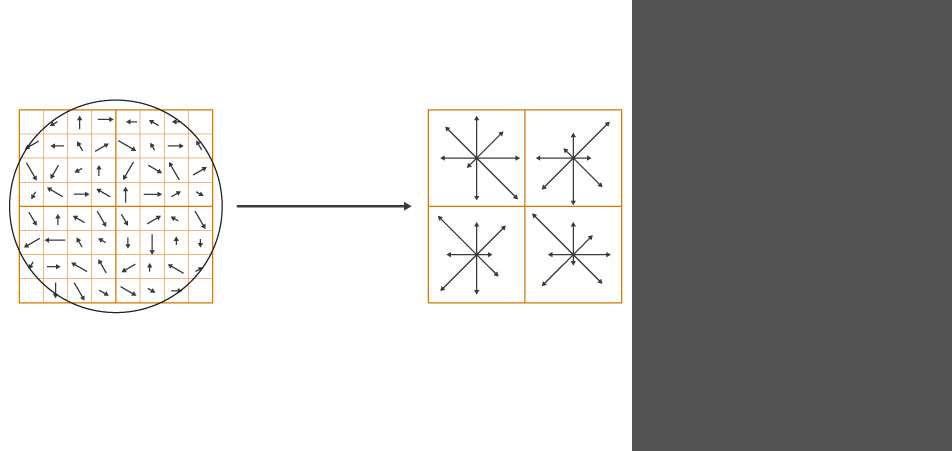
SIFT - Descriptor
The SIFT (Scale Invariant Feature Transform) Descriptor carries similar abilities as the HD detector thus it masters also the transformation of the feature regions.
The Harris Detector detects the points and the SIFT Descriptor has then to classify them.
In the end there are a lot of such vectors that are responsible for the correct assignment of the image contents.
-

01 Imageretrieval with the aid of physical properties, the so called "low level" features
You can distinguish the image's physical features approximately into three parameters:
- luminance
- contrast
- hue
-

01 Imageretrieval with the aid of physical properties, the so called "low level" features
- size
- texture, based on luminance and contrast
-

02 Implementation
Classification structures of the images' physical properties can be easily described with some simple models of the explorative data analysis.
Simple, clear, easy to understand explorative methods for data bodies work with one or two variables.
The word as the controlling tool and medium of navigation
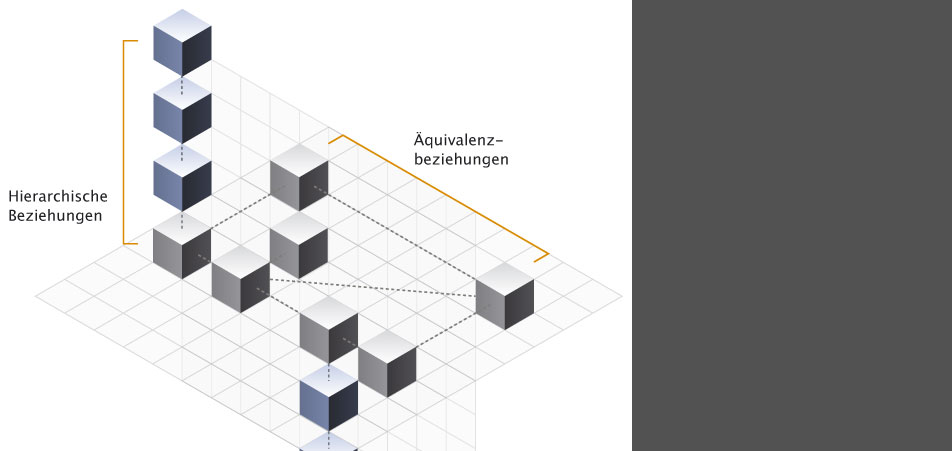
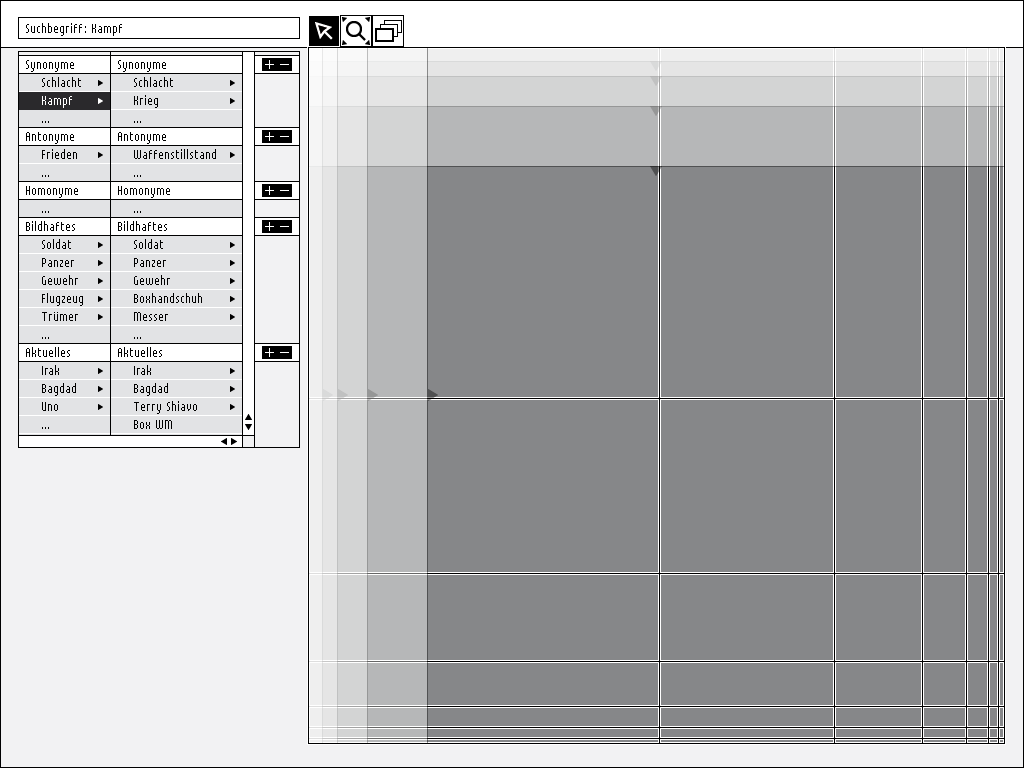
One module of the interface should certainly allow to look for pictures by verbal describing of the seeked image.In the beginning it appears to be easier to classify images hierarchicly according to their theme.
-
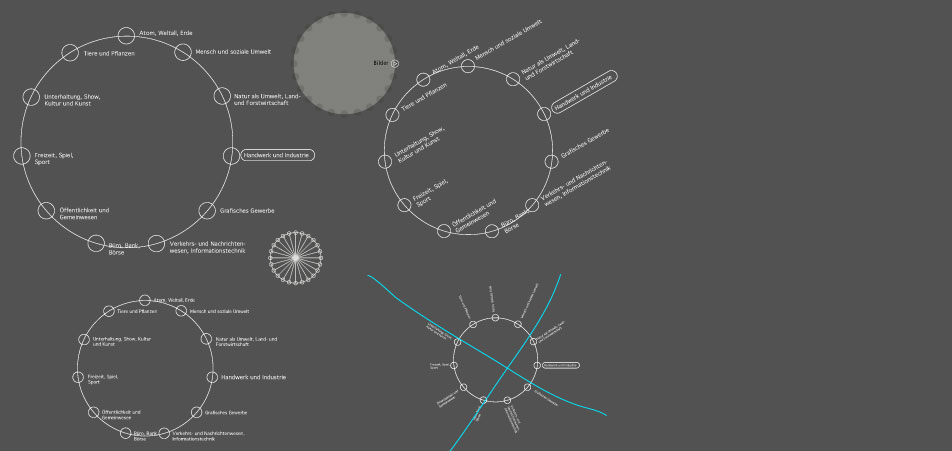
Another approach translating the list structure to a circular shape.
-
In my opinion this type of a hierachical presentation seems to give the user the best overview, because he can backtrack the way he turned on his search. Besides it gives me the possibility of scaling thus it creates space for other modules.
-
First rough arrangement
- verbal search (top left)
- preview module (beneath verbal search)
- main "search results" panel
-
First rough arrangement
Page 6 zoomed in
-
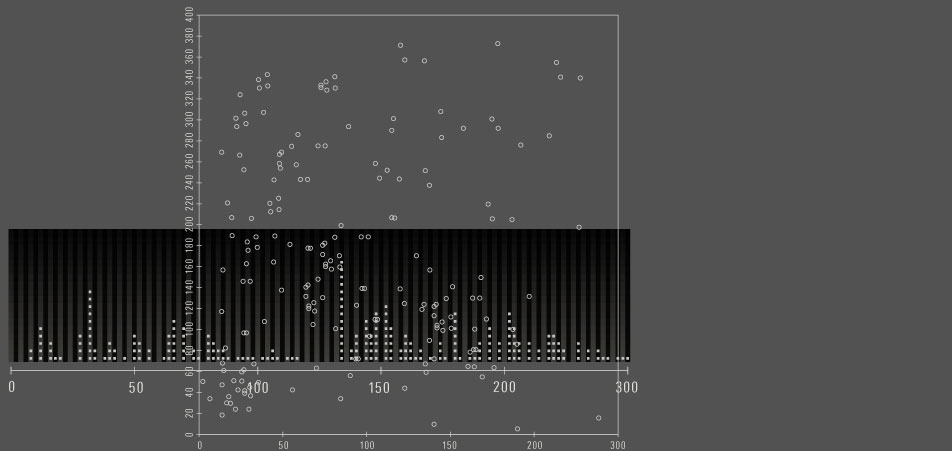
Possible models of explorative "data analysis"
The so called "scatterplots" are suited for the representation of huge data amounts because they don't have any restriction to the amount of possible value occurence.
One distinguish between onedimensional, twodimensional and multidimensional scatterplots.
-
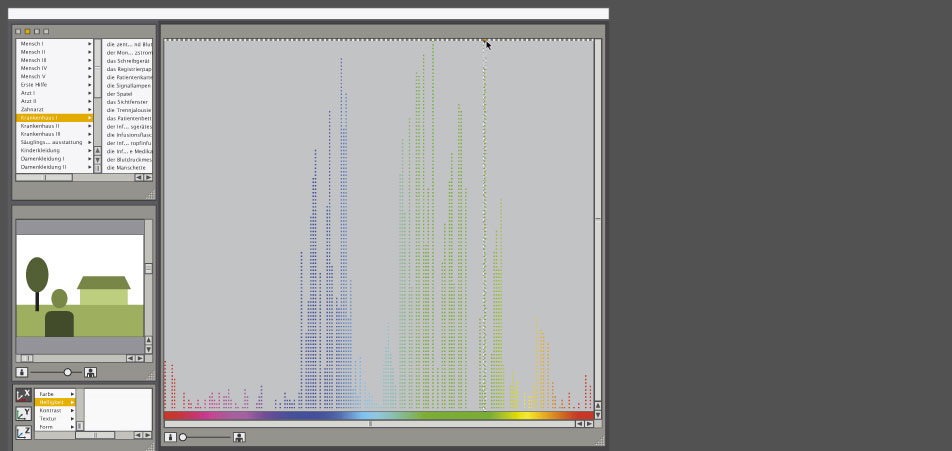
Possible models of explorative "data analysis": implementation I
-
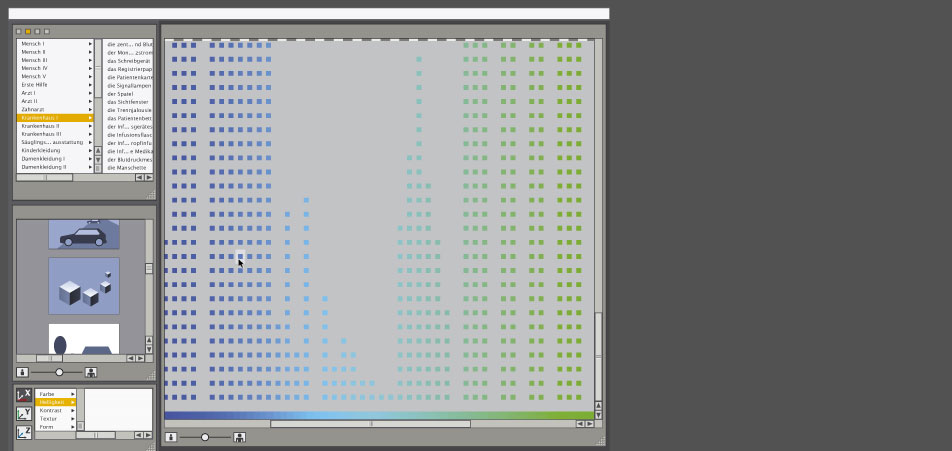
Possible models of explorative "data analysis": implementation II
-
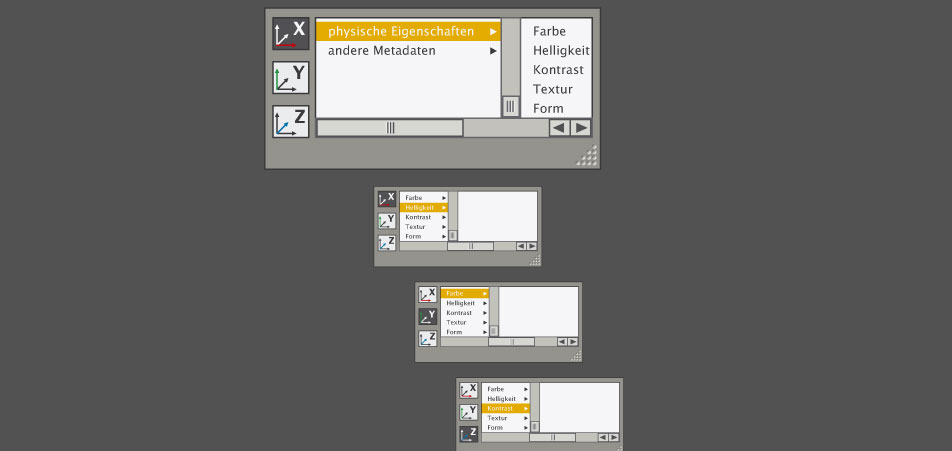
Dynamic parameterization
One should have always the ability, depending on the number of variables/dimensions, to change the parameters of the different axis.
-
Dynamic parameterization: implementation I
-
Dynamic parameterization: implementation II
-
Semantic Search
As you cannot always assign images directly to a term it is necessary tp create a parametric "wanted poster" with the aid of a verbal thesaurus classification system which would lead you close the seeked picture.
-

Idea of classification priorities
In the query you can put several parameters. Pictures that meet the criteria most adequately "step forward", become focussed while as the other results "dive" into the background.
-
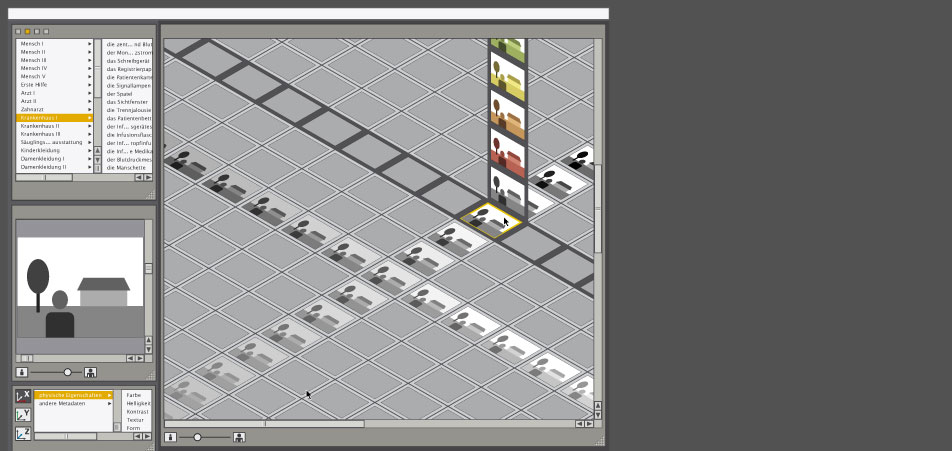
First fisheye attempts
-

First fisheye attempts - Implementation
On the left side you can see the thesaurus access where the "wanted poster" can be created and the main viewport contains the results with those fullfilling more required parameters in the foreground and the less important results in the background.
-
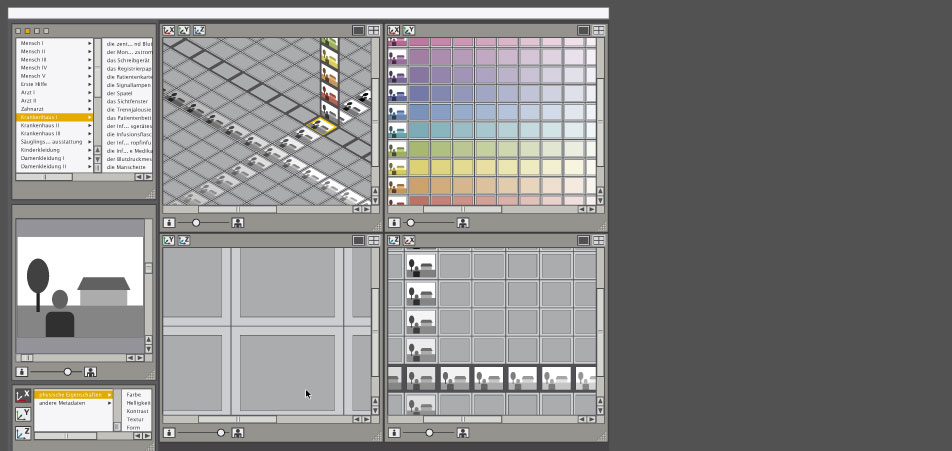
Another attempt with parameterized query
Unfortunately this kind of idea only works with three parameters, optionally in a threedimensional space with one additional, the fourth parameter.
-

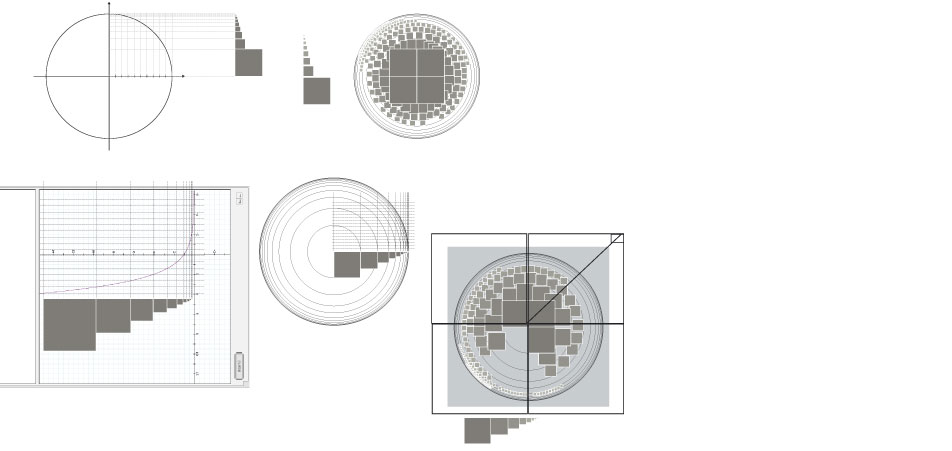
Fisheye generalisation I
The problem of the normal concentric arrangement of the images within the fisheye was that you could assign only one parameter to this space, just the one on the z-axis.
In my recommended generalized fisheye the focus lies in the top-left area of the viewport. You damage on the one hand the intuitional concept of the fisheye metaphor a little bit but there are some important pro arguments.
The first argument is that you can parameterize two axis now X and Y and you'll get later the focus of two modules that lie beside each other closer. ...aaand it fits better for smaller displays.
Here you can see two examples of a graphical derivation from a mathematical function typical for fisheye calculations where a variable has been modified several times.
-

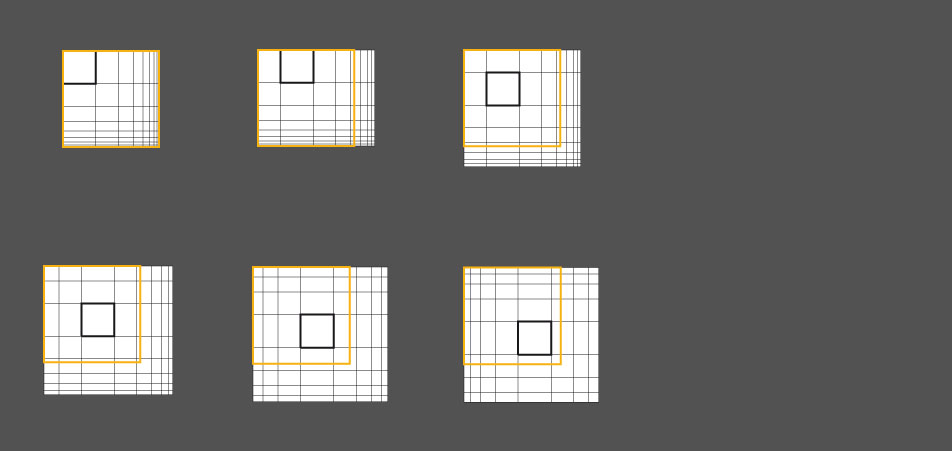
Fisheye generalisation II
Here you can see another examples of a graphical derivation from a mathematical function typical for fisheye calculations where a variable has been modified several times.
In the beginning there was also the idea to give the user the possibility to control the array settings of the fisheye viewport but then after further examination I chose the 8x8 matrix.
-
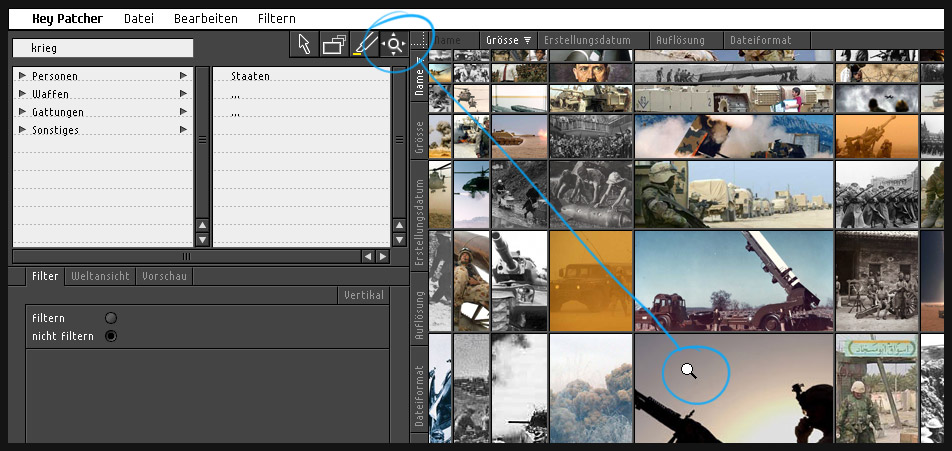
Viewport navigation tools: "Move-Magnifier-Tool"
In the default positioning the magnifier is located in the top-left corner of the viewport. With this tool you have the possibility to move the magnifier/the focus around to enlarge the results of the peripheries.
-
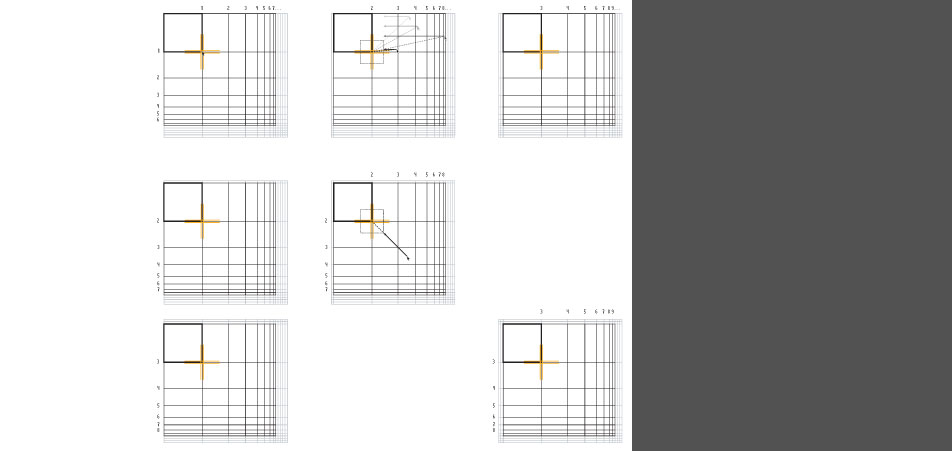
Viewport navigation tools: "Rummage-Tool"
With this tool activated a register mark appears on the right-bottom corner of the "first" result which is a reference for the mouse cursor within the viewport matrix.
Depending on the position of the cursor to this register mark the whole matrix can be moved around by a simple hover effect in any direction to reveal the covered / in the viewport not visible yet / laying beyond the borders of the viewport results.
-

First visualization attempts
In the beginning I constructed the interface with a vector-based application in order to have more flexibility of changing some parameters like e.g. the size of the different modules.
First rough positioning of the ontology (semantic verbal search) module + the viewport for the result data
-
First visualization attempts
Elaboration of the ontology module
-
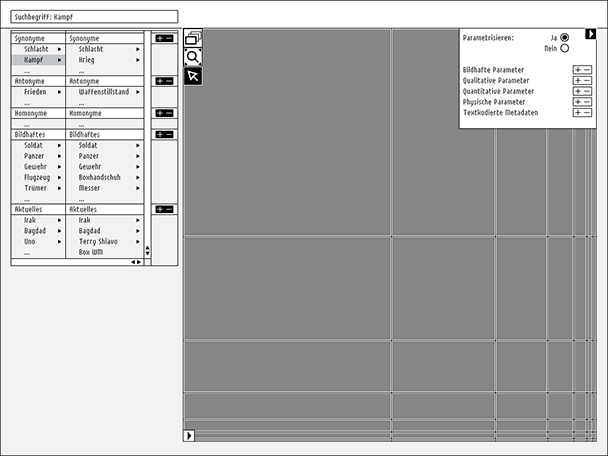
First visualization attempts
Approach for the direct parameterization on the axis
-

-
Parameterization dialog box
One of the first ideas concerning the positioning of the parameterization dialog or menu respectively, was putting them directly on the axes.
Here you can see some methodology designing such a rather simple dialog box.
-

First visualization attempts
Enhancement of the dialog in the parameter box
-
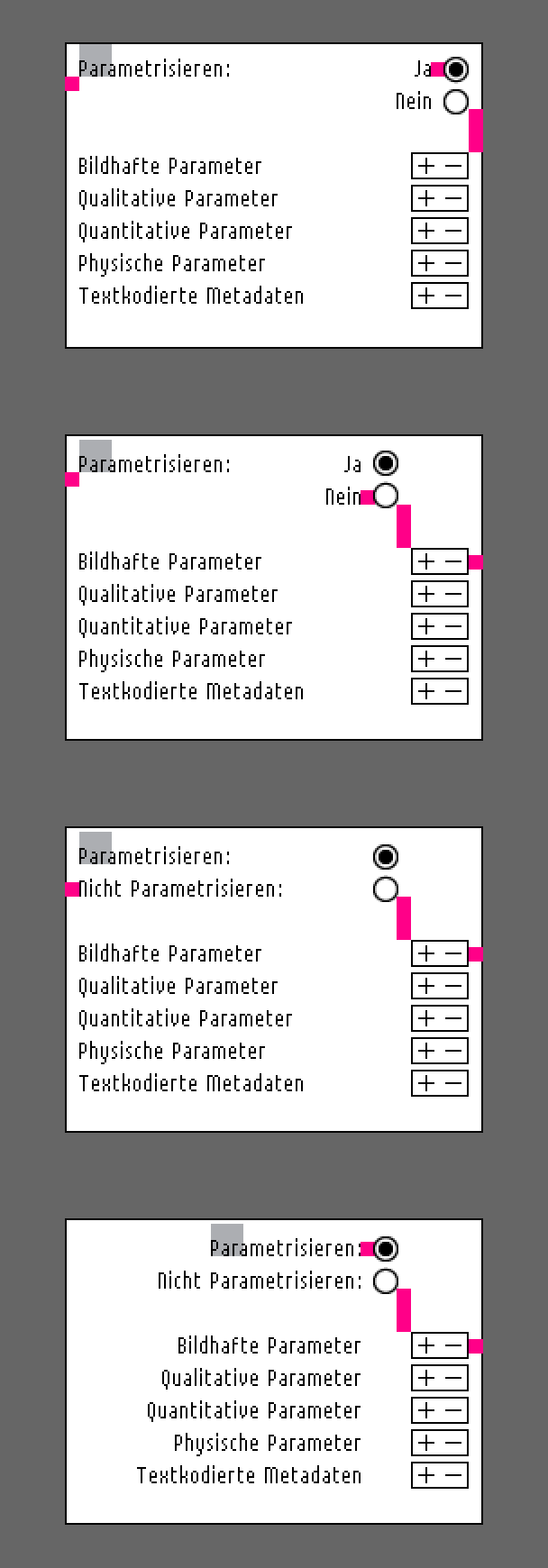
First visualization attempts
How much space do the dialogs in the filter modules need?
Some parameters have got more complexity than the others and therefor could need more space. Thus the next step was using the whole length of the axes for the dialog box.
-
First visualization attempts
Applying one of the parameterization methods, now I could test some typographic issues exploring a little bit the available space possibilities in the dialog boxes.
What I learned from that was that writing down all the input or parameters needed later in the interface on paper and in sketches, one has to try something out immediately and see if it could work at all.
Here you can see some attempts with a 13px bitmap font changing the line height and exploring gaps in order to give semantic groups their own visual identity.
I would say that user interface typography has its own challenge and it differs a little bit from the classic print typography.
-

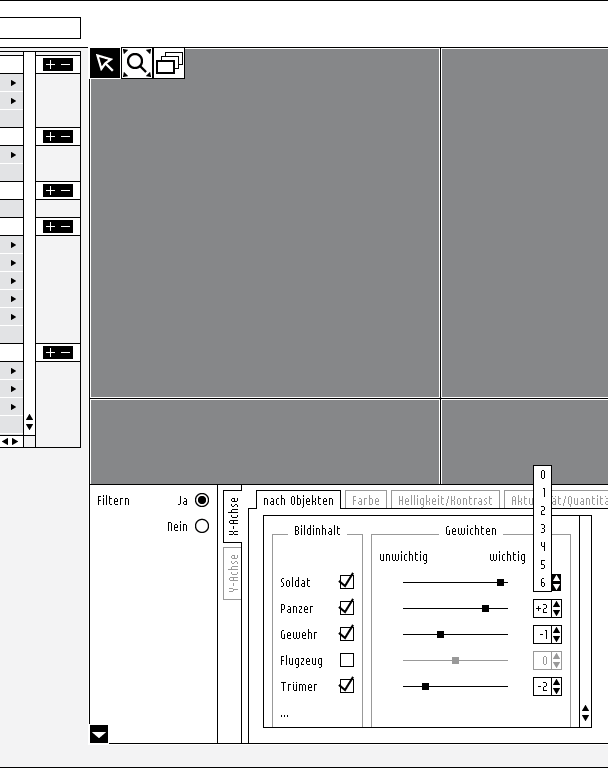
First visualization attempts
The problem is when applying the dialog box to the y-axis in the same manner as with x-axis in order to emphasize which axis you are actually manipulating, well you run out of space if you wnat to keep things slim and not to cover the search result data.
-
First visualization attempts
Besides allocating the parameterization dialog boxes directly on the axis forces me to put the main navigation tools into another area (as you may have noticed already on page 7).
-
First visualization attempts
One possibility to avoid the problems described on the last pages would be a floating dialog box at the bottom where you could choose the desired parameterization axis.
-
First visualization attempts
Along the way I realized that the data amount can be parameterized in two different main steps. Step one allows to parameterize the data with the conventional metadata parameters like calender date, name and size directly on the axis (take a look e.g. on the iTunes list). Step two allows to filter data with dynamic parameters like the semantic and physical properties delivered by the new technology algorythms.
Moreover the arrangement for the space of the different modules evolved.
-

First visualization attempts
Dynamic parameters like the semantic and physical properties live inside a third module settled beneath the ontology module (left of the main viewport).
-
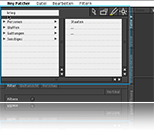
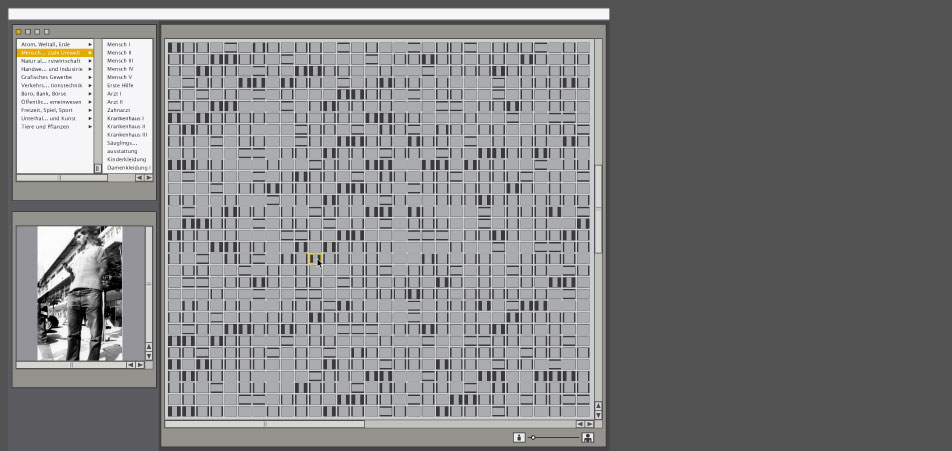
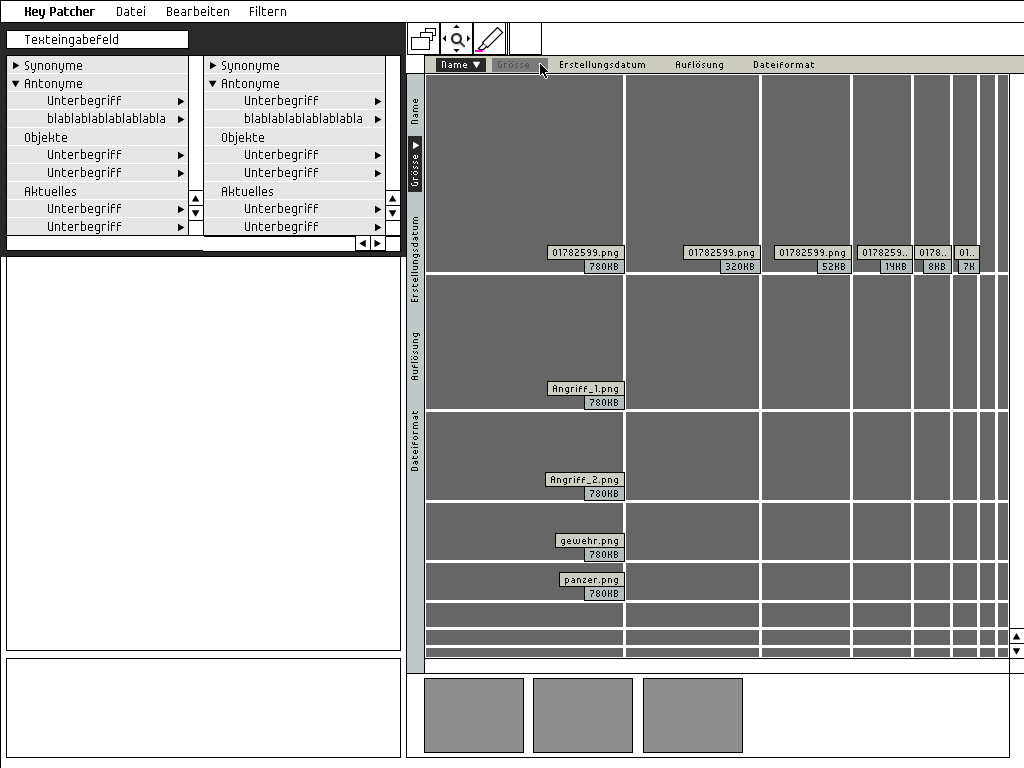
keypatcher
-
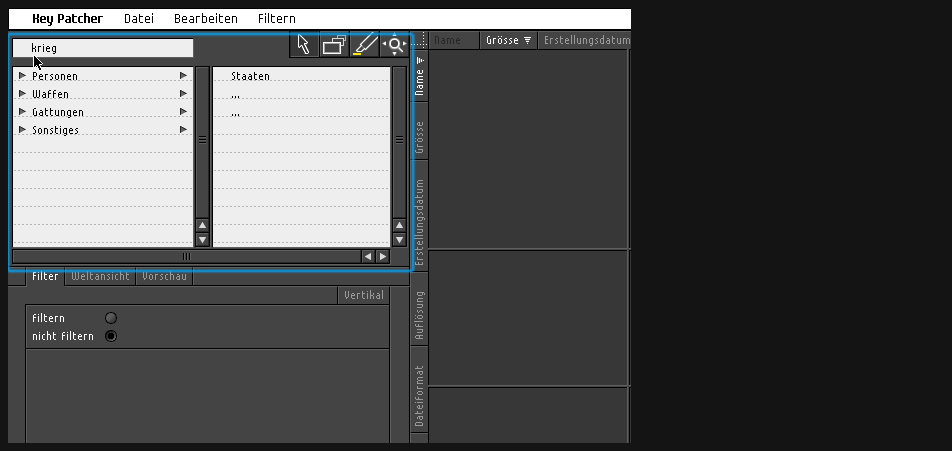
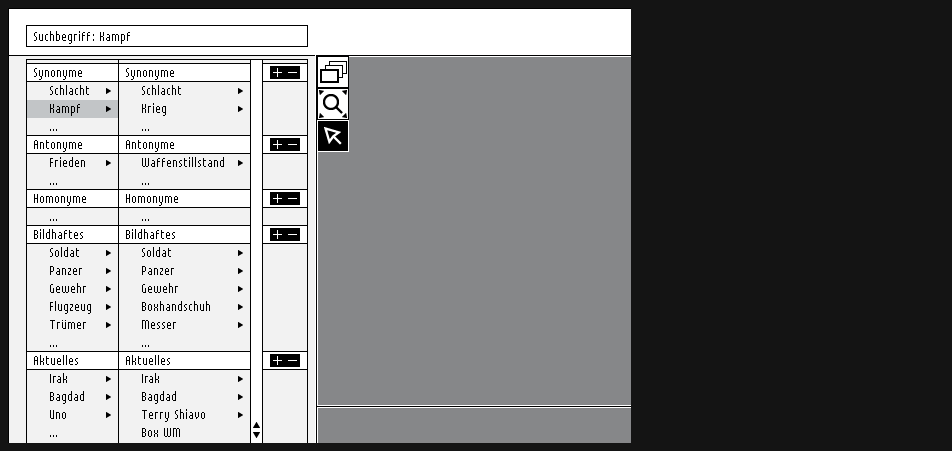
keypatcher - Thesaurus
The Thesaurus module as the verbal access for an image search
-
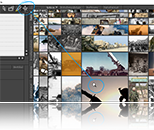
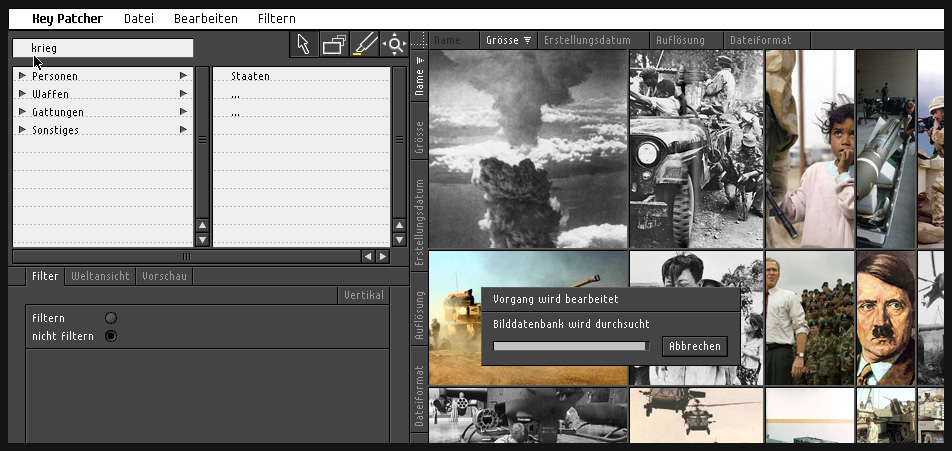
Final visualization
Main viewport presenting the image data results
-
-
-

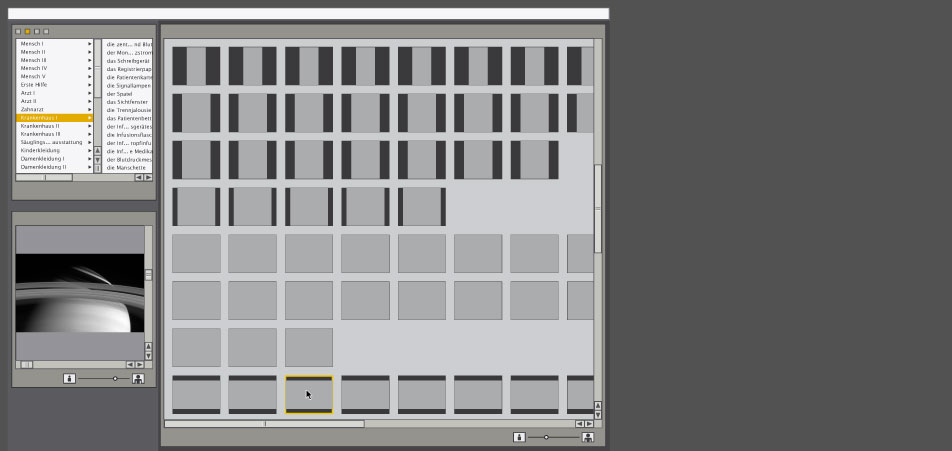
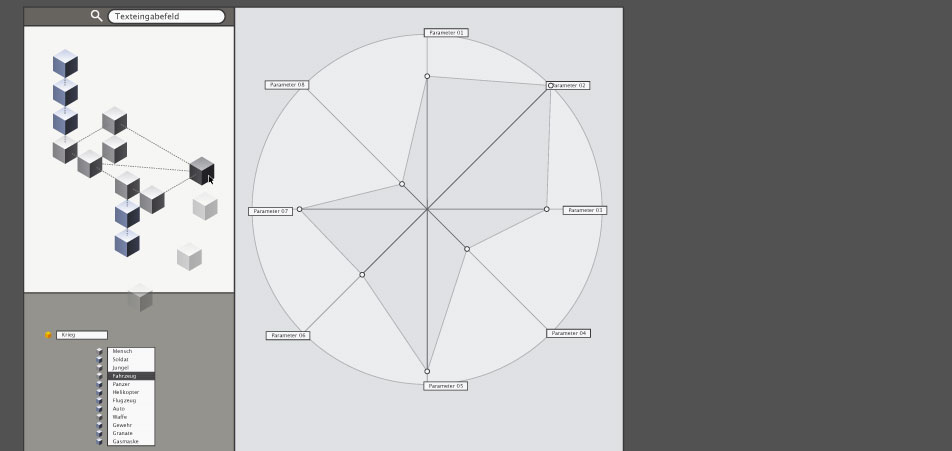
keypatcher - Konventionelle Parameter
200% zoom on the conventional parameterized axis and the navigation tools
-
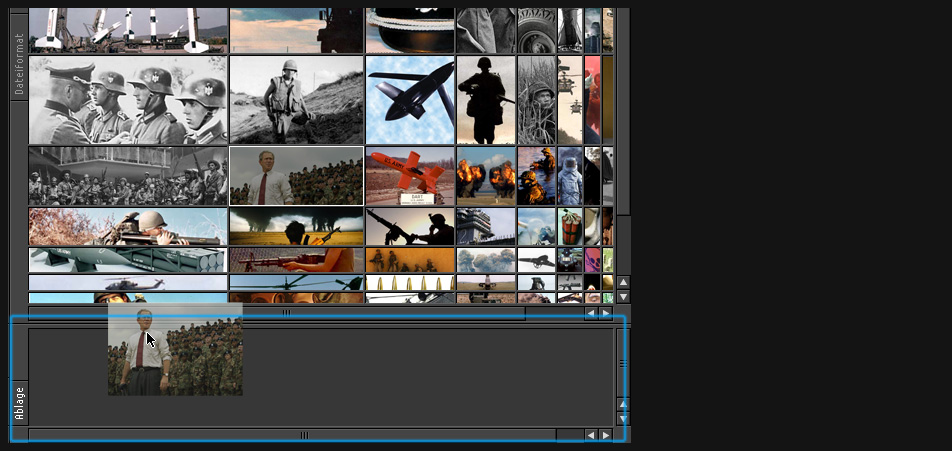
keypatcher - Ablagefach
Backup storage container for saving the collected results
-
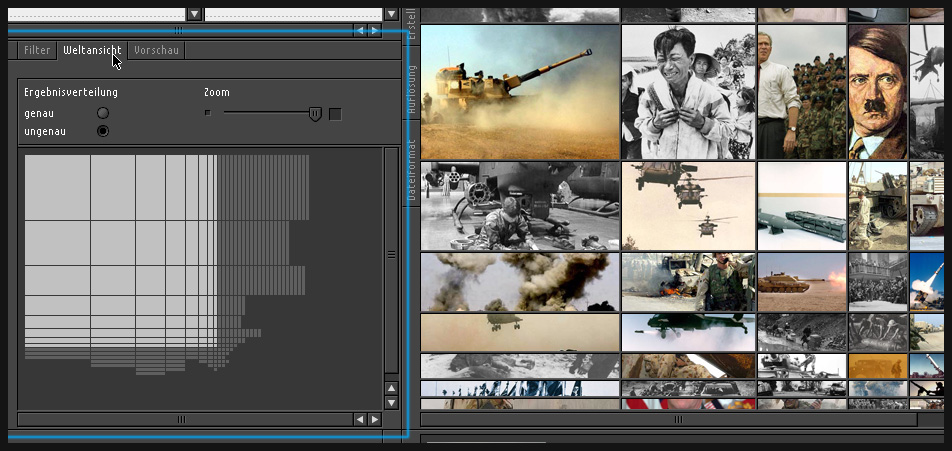
Final visualization
The global "overview module": How many results lie beyond the main viewport borders?
-
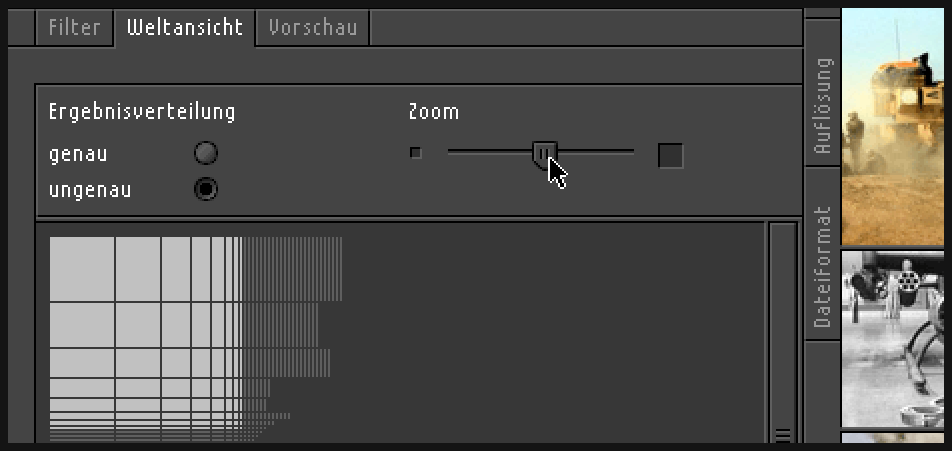
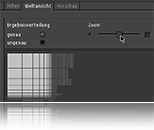
Final visualization
200% zoom of the global overview module, zooming out
-
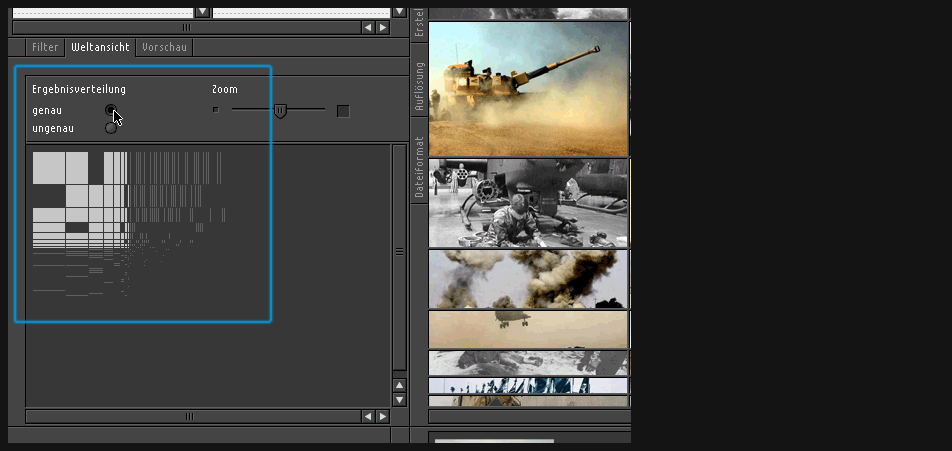
keypatcher - Result "Fuzziness"
Global overview switched to an accurate presentation of the results amount: Since every picture is described by a number of values and properties e.g. an image starting with A would leave an empty gap to his neighbour starting with C.
-
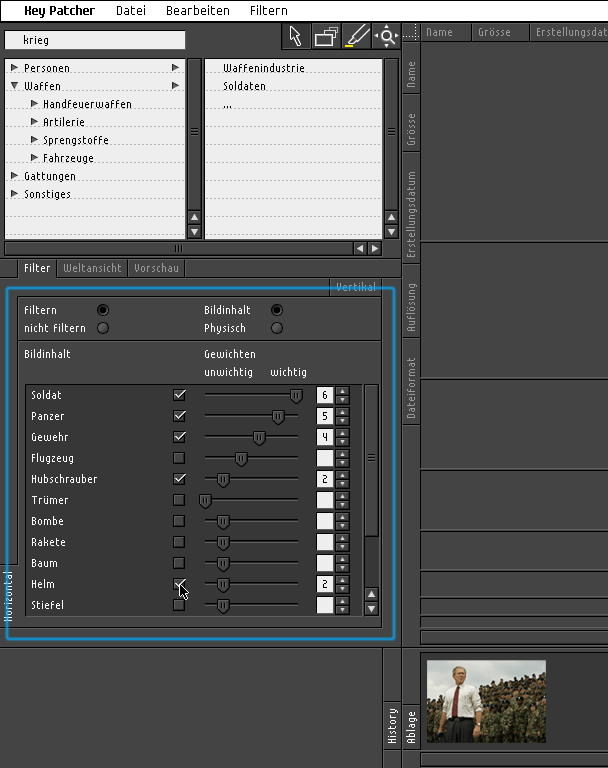
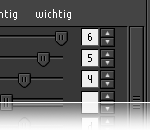
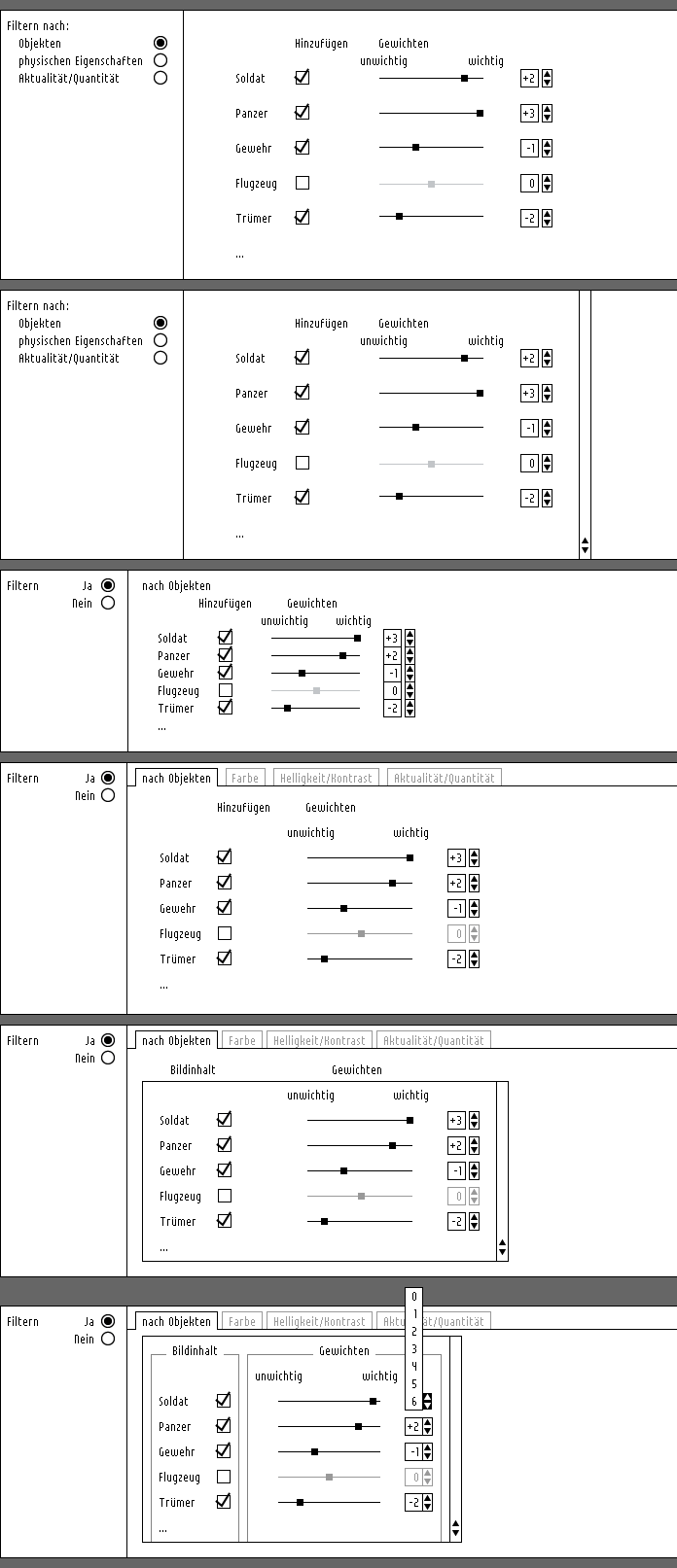
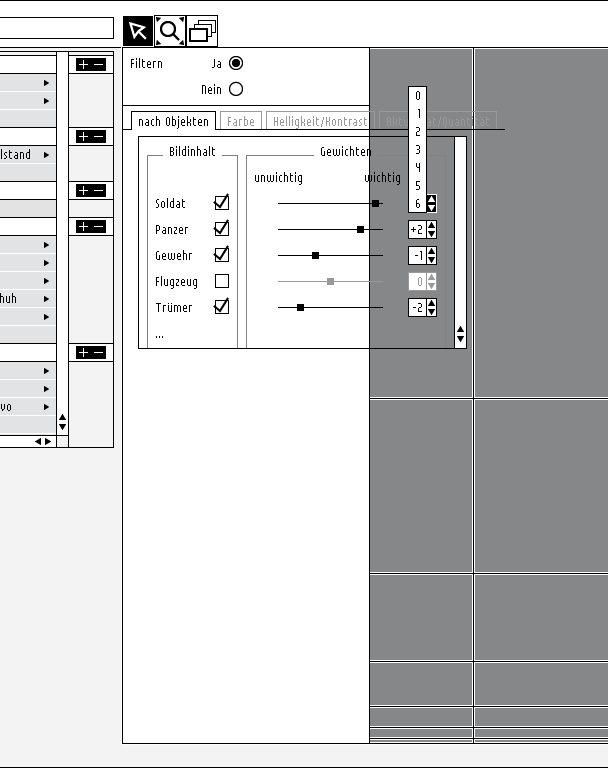
keypatcher - Image Content Weighting
Finally you can filter the data according to the possibility of the new technology approach.
That means that if the computer can recognize the image content it would be thinkable making yourself a kind of a 'wanted poster'. Imagine you could weight the individual contents according to your purposes. You are looking for pictures with dogs and cats on them but dogs are more important to you than cats so you would be already happy with images that only contain dogs? Well, just mark / weight it with the slider in the objects-filter-module or give the dog a higher number.
-
This project still needs some tweaking
Yes I know, every project is never ready but here I would like to spend some extra time in the future to make some things more visible, more obvious. Well, e.g. some people shake their heads when they see which image topic I chose ('war') to present the filtering of the search result data. I must defend this decision though, because it is the war pictures or in general images about violence that are so present in the public media. Moreover I had to choose a term that makes it impossible to adress an explicit image to it. But hey, with 'love' I would have put some pornographic image data into the project, wouldn't I? ...
Ok, so maybe I could change the term images are applied to, but what should be done more urgently is e.g. some animations that show the main viewport handling the result data. However this won't be easy because it isn't a linear movement but a more sophisticated fisheye enlargement and movement.
| interface | Project interface / "dissertation" |
Metadata | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Date | 2005 | ||||||||||
| Size | 40kb | ||||||||||
Content dissertation: investigation / approaches / visualization / conclusion |
 |
Duration | 4 months | ||||||||
| Media | digital | ||||||||||
| Applications used | |||||||||||
| Photoshop | Director | ||||||||||
| Illustrator | Indesign | ||||||||||
| contact me! | H | ||||||
|---|---|---|---|---|---|---|---|
| H | |||||||
| H | |||||||
| Address | |||||||
| Name | Klaudiusz Szatanik | ||||||
| Street | Ulmer Strasse 48 | ||||||
| City | 73066 Uhingen | ||||||
| Fon | 0173 3030301 | ||||||
| racl@klaudiusz.de | |||||||